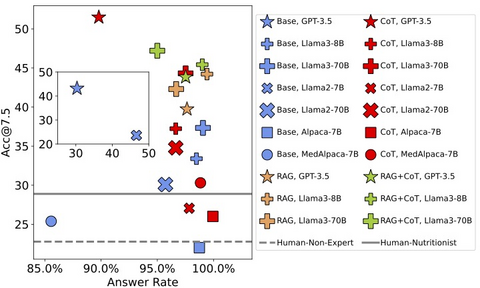
Результаты исследования точности подсчета углеводов для разных моделей
Исследователи Калифорнийского университета собрали набор данных NutriBench, который состоит из 5000 проверенных людьми описаний блюд с метками макронутриентов, включая углеводы, белки, жиры и калории.
Основное отличие датасета от обычных списков состава продуктов, в том, что он адаптирован для использования в режиме естественного диалога. Пользователи подобных таблиц знают, как сложно на глазок правильно определить вес блюда, а постоянно носить с собой весы не удобно. Кроме того, LLM пока испытывают определенные трудности при работе с табличными данными, поэтому данные уже адаптированы для применения в RAG
Поэтому для удобства использования данные разделены на 15 подмножеств, которые включают описания блюд, различающиеся по количеству продуктов (1-3), типу порций (одиночные или множественные), описаниям размера порций (натуральные, например, «1 чашка», или метрические, например, «50 г»), а также популярности продуктов.
Датасет позволяет обучить модель или выступить в качестве базы знаний для ответа на вопрос «сколько углеводов я получила, съев на обед большую тарелку пасты Карбонара и выпив чашку кофе?».
К датасету также прилагаются результаты исследований на разных моделях, например GPT-3.5 с промптом CoT достигает наивысшей точности 51,48% с частотой ответов 89,80%.
Датасет доступен для использования в некоммерческих целях. Скачать и попробовать обучить своего бота можно тут
P.S. Если вам интересны новости про генеративный ИИ, LLM, мультиагентов, я рассказываю об этом в своем Телеграм канале https://t.me/generative_ai_ru
Источник: habr.com