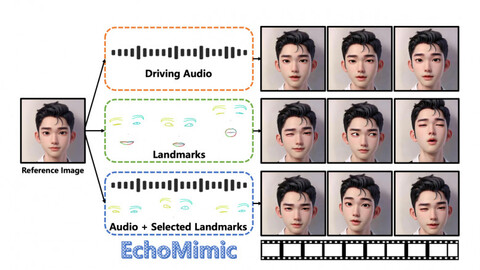
Исследователи представили нейросеть EchoMimic для генерации реалистичной лицевой анимации по редактируемым маркера лица и аудио. Особенность метода в том, что сохраняется исходное изображение.
EchoMimic разработан на базе генеративных моделей Stable Diffusion, а для распознавания референсов, аудио и характеристик лица используются дополнительные модули Audio Encoder, Landmark Encoder и Reference U-Net. На вход нейросеть получает изображение и запись голосу, а на выходе пользователь получает видео с анимацией. Нейросеть самостоятельно распознаёт лицевые маркеры: положения глаз, носа и губ.
Разработчики протестировали свою модель и отметили, что EchoMimic работает лучше и быстрее похожих решение, например, AniPortrait и SadTalker. Метод проверяли на различных наборах данных и метриках.
EchoMimic можно запустить локально. Разработчики рекомендуют использовать не менее 16 ГБ видеопамяти. Нейросеть будет работать и на меньшем объёме памяти, но тогда увеличится время генерации. Инструкция по установке опубликована на GitHub. Также разработчики выложили текст исследовательской работы и поделились кодом на площадке Hugging Face.
Источник: habr.com