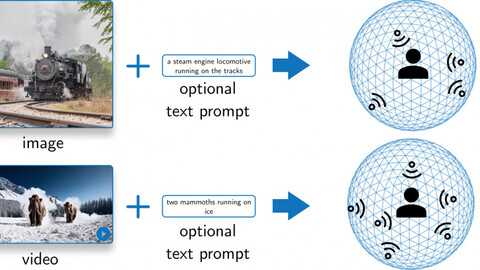
Исследователи Университета Торонто представили See-2-Sound — нейросеть для генерации звуков окружения по картинке или видео. Модель машинного обучения не только создаёт подходящую дорожку, но и расставляет источники звука в пространстве для создания эффекта присутствия.
See-2-Sound работает в несколько этапов:
Нейросеть получает на вход изображение, анимацию или видео и оценивает источники. Тут модель пытается понять, какие объекты могут издавать звуки и природу этих звуков.
На основе полученных данных генерируется звук. Для каждого источника создаётся собственная дорожка.
Сгенерированные аудио расставляются в виртуальной комнате относительно пользователя, что создаёт объёмное звучание и эффект присутствия в кадре. На выходе получается аудио в формате 5.1.
Нейросеть можно установить по инструкции в репозитории или запустить в контейнере. Инференс модели выглядит следующим образом:
import see2sound config_file_path = «default_config.yaml» model = see2sound.See2Sound(config_path = config_file_path) model.setup() model.run(path = «test.png», output_path = «test.wav»)
Исследователи опубликовали текст работы и код, а на сайте See-2-Sound доступны примеры. На платформе Hugging Face есть демо, в котором можно попробовать нейросеть на собственных входных данных.
Примеры работы нейросети
Источник: habr.com