В новом исследовании, опубликованном в журнале Nature, ученые из Университета Оксфорда представили метод, способный обнаруживать «галлюцинации» в работе больших языковых моделей искусственного интеллекта (ИИ). Этот прорыв может значительно повысить надежность ответов ИИ в областях, где ошибки могут иметь серьезные последствия, таких как юридическое и медицинское консультирование.
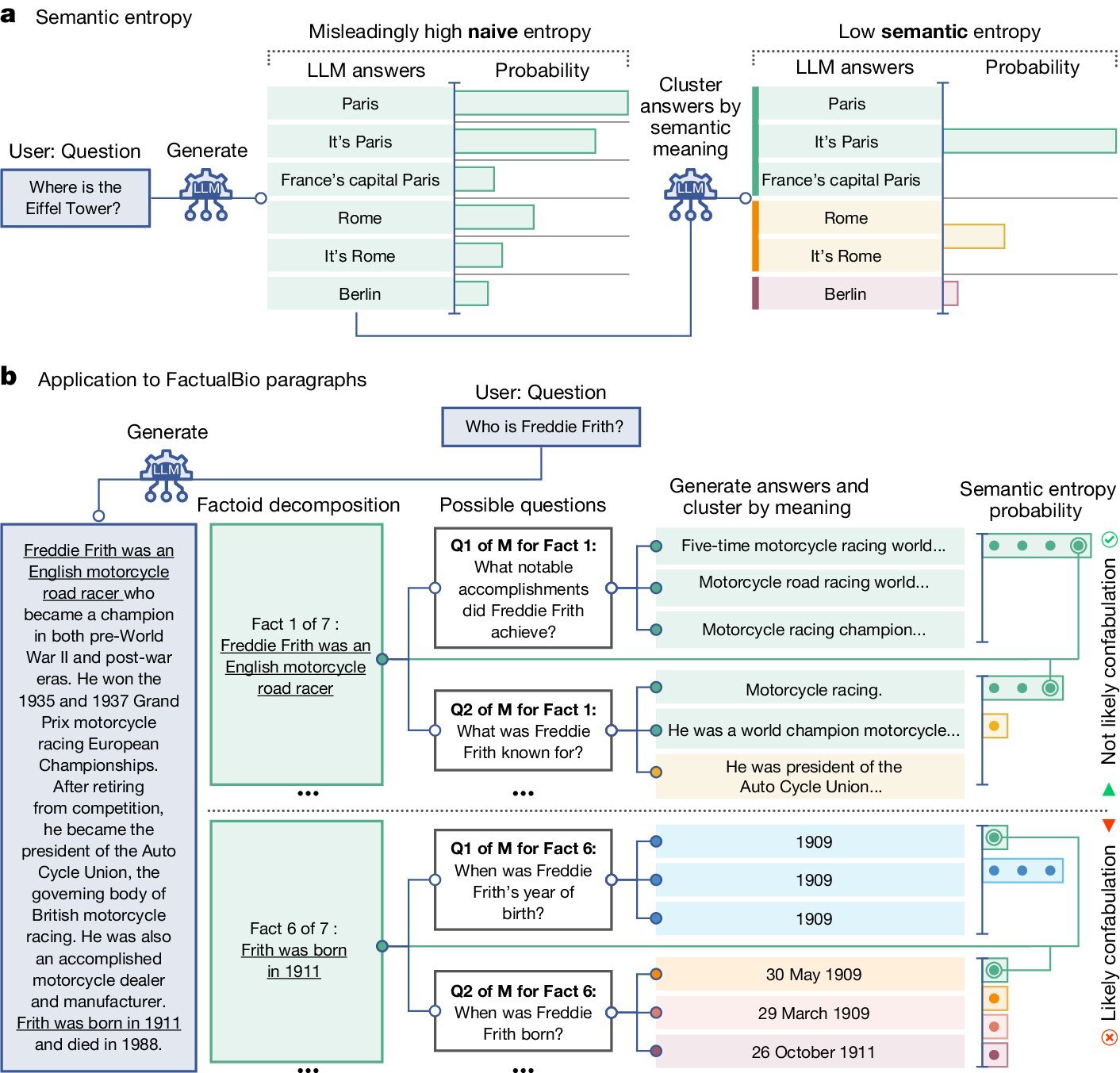
Исследователи сфокусировались на случаях, когда ИИ выдает разные ответы на одинаковые вопросы, что называется конфабуляцией. Они разработали метод на основе статистики, позволяющий оценивать уверенность модели в смысле ответа, а не только в его формулировке.
Испытания показали, что новый метод значительно эффективнее предыдущих при выявлении ошибок ответов на широком спектре данных, включая биомедицинские вопросы и математические задачи. Это направление исследований призвано улучшить надежность искусственного интеллекта в критически важных областях.