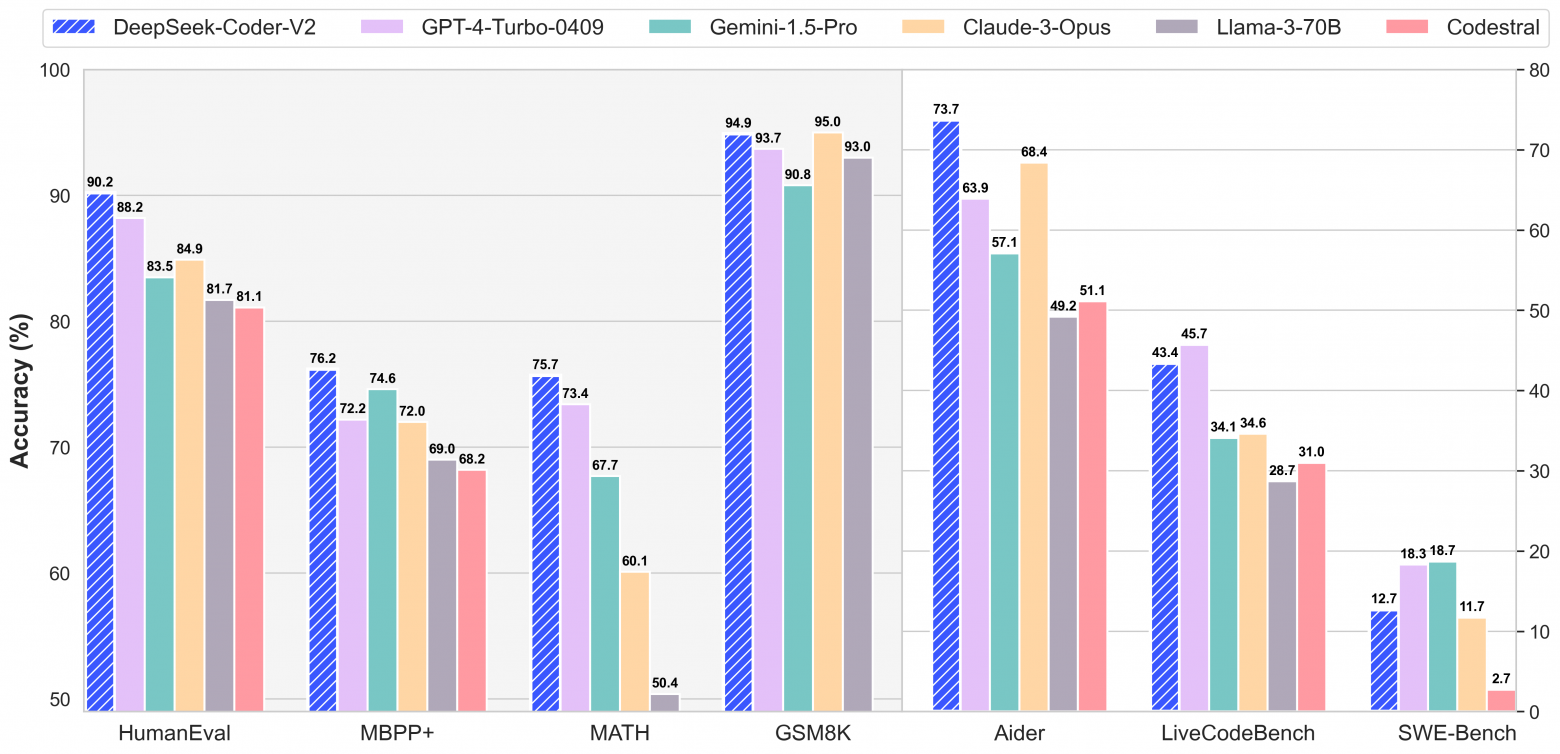
DeepSeek, вслед за своей моделью DeepSeek-V2, представила модель специализирующуюся на коде DeepSeek-Coder-V2. Модель представлена в двух видах: DeepSeek-Coder-V2 размером 236B и DeepSeek-Coder-V2-Lite размером 16B. Старшая модель в большинстве представленных бенчмарков обходит платных конкурентов.
DeepSeek-Coder-V2 — построена на архитектуре MoE (Mixture-of-Experts), что означает, что в момент инференса активна только часть весов (2.4B и 21B соответственно для старшей и младшей модели), что ускоряет генерацию. Размер контекста 128k.
Младшая модель на 16B (активных параметров 2.4B) по некоторым бенчмаркам обходит Codestral 22B, которая является лучшей средне-малой моделью для генерации кода, что делает новую модель достаточно интересной для тестирования в качестве локального copilot.
Для запуска в качестве локального copilot, можно воспользоваться continue или codegpt — оба проекта умеют запускаться на локальных моделях, и помимо дополнения кода, предоставляют интерфейс для анализа, рефакторинга, переписывания и доработки кода.
Для запуска локальных моделей с api можно воспользоваться text-generation-webui, или koboldcpp (koboldcpp-rocm если у вас AMD карта), или ollama.
Онлайн чат (требует регистрация на почту, номер телефона не требуется): https://chat.deepseek.com/coder
github проекта: https://github.com/deepseek-ai/DeepSeek-Coder-V2
gguf Coder-v2: https://huggingface.co/LoneStriker/DeepSeek-Coder-V2-Instruct-GGUF
gguf Coder-v2-lite: https://huggingface.co/LoneStriker/DeepSeek-Coder-V2-Lite-Instruct-GGUF
Среди других интересных новинок Nvidia представила открытую LLM модель Nemotron-4 размером 340B.
Источник: habr.com