Учёные из Института искусственного интеллекта AIRI совместно с коллегами из SberAI и «Сколтеха» нашли новое свойство больших языковых моделей и научились контролировать его. Новое открытие позволит оптимизировать модели на 10–15% без потери в качестве. Также найденное свойство снижает количество вычислительных мощностей, необходимое для их использования. Статья с исследованиями была принята на конференции в сфере ИИ — ACL 2024 (Main Track, Core A).
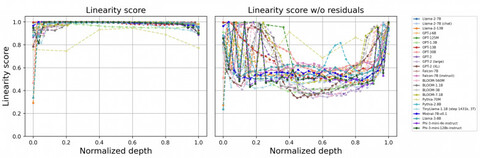
Как рассказали в AIRI, трансформер представляет собой тип архитектуры моделей, который привёл к революции в развитии ИИ. Именно благодаря этому типу возможно развитие популярных диалоговых ботов. Любая архитектура состоит из большого количества слоёв, через которые от «входа», например, запроса «нарисуй котёнка», информация доходит до «выхода» и преобразуется в картинку. Считается, что свойство слабых моделей — это линейность слоёв, а сильных — нелинейность (тех самых трансформеров). Линейность позволяет создавать модели более простыми и эффективными в вычислениях, но не позволяет модели решать сложные задачи, например, выучивать необычные закономерности в данных.
Иван Оселедец
Доктор физико-математических наук, генеральный директор Института AIRI, профессор «Сколтеха»
«Нам удалось изучить модели под микроскопом. Простыми средствами описать сложные процессы внутри трансформеров и сразу предложить эффективный регуляризатор. Уже проверили всё на маленьких моделях, проверки на больших моделях и обучении — впереди. Обнаруженный эффект кажется очень контринтуитивным, он противоречит многим представлениям о глубоком обучении. В то же время, именно он позволяет тратить меньше вычислительных ресурсов на развёртку и инференс больших языковых моделей. На днях мы выложили препринт статьи, а она уже обогнала публикации от Google, Microsoft, MIT, и Adobe в списке статей дня на HuggingFace. Понимая важность работы для научного сообщества, мы поделились регуляризатором с коллегами и опубликовали его в открытом доступе».
Коллектив учёных из AIRI, SberAI и «Сколтеха» изучили устройство 20 известных open-source языковых моделей типа декодер и выяснили, что между эмбеддингами есть высокая линейная зависимость. Так, при переходе от слоя к слою информация не получает нелинейных преобразований, и сложную архитектуру трансформера можно заменить лёгкими слоями нейросети. Чтобы избежать негативных свойств линейности во время предобучения, исследователи разработали специальный «регуляризатор», позволяющий контролировать проявления линейности и улучшать метрики качества.
Благодаря возможности контролировать проявления линейности, учёные заменили сложные блоки слоёв модели на простые. В ходе экспериментов выяснилось, что облегчать без потери качества можно 10-15% слоёв. Далее модель начинает терять полезные навыки. Получить доступ к регуляризатору можно по ссылке.
Андрей Белевцев
Старший вице‑президент, руководитель блока «Технологическое развитие» «Сбербанка»
«Одним из вызовов развития AI‑технологий, в особенности больших языковых моделей (представителей ветки GenAI), остаётся потребность в вычислительных ресурсах для обучения следующего поколения SOTA‑моделей. В основе большинства архитектур GenAI лежат блоки трансформеров, и в опубликованной работе выявлена линейность в некоторых представлениях данных внутри этих блоков. Как следствие, это позволяет существенно оптимизировать архитектуры с точки зрения вычислительных мощностей, снизить нагрузку, получить результат за меньшее время за счёт адаптивной регуляризации. Потенциал сокращения вычислительных ресурсов на обучении оценивается в порядке до 10%. Мы, в „Сбере“, планируем провести тестирование рассмотренной идеи и в случае успеха — тиражировать её на флагманские модели GenAI. Поиск таких смекалок в AI‑архитектурах позволяет частично компенсировать вычислительный голод, поэтому продолжим поддержку таких исследований в направлении обучения больших моделей».
Источник: habr.com