Летом прошлого года AMD, Arista, Broadcom, Cisco, Eviden/Atos, HPE, Intel, Meta✴ и Microsoft сформировали консорциум Ultra Ethernet (UEC), призванный составить конкуренцию технологии InfiniBand, которая фактически единолично контролируется NVIDIA после покупки Mellanox, и стандартизировать Ethernet-решения для современных ИИ- и HPC-платформ. А теперь AMD, Broadcom, Cisco, Google, HPE, Intel, Meta✴ и Microsoft сформировали альянс Ultra Accelerator Link (UALink), который должен составить конкуренцию NVLink.
К UEC за год присоединились ещё полсотни компаний, кроме, конечно, NVIDIA, которая, впрочем, про Ethernet тоже не забывает, хотя периодически получает критику со стороны Broadcom. Единственной альтернативой в деле построения фабрик для более-менее крупных кластеров остаётся Omni-Path Express, развиваемый Cornelis Networks, которая тоже присоединилась к UEC, но доля этой технологии на фоне Ethernet и InfiniBand мизерная. Кроме того, ни одна из этих технологий не может предложить то, что может NVIDIA NVLink — возможность напрямую объединить сотни ускорителей (точнее, их память) сверхбыстрым соединением с низким уровнем задержки.
Источник изображений: UALink via ServeTheHome
NVLink 4 достиг скорости 900 Гбайт/с на ускоритель и впервые вышел за пределы узла, позволив объединить в домен до 256 ускорителей, что NVIDIA и предложила в рамках DGX SuperPod H100. NVLink 5 удвоил пропускную способность до 1,8 Тбайт/с и теоретически позволит объединить до 576 ускорителей в одном домене. Именно NVLink позволил создать высокоплотные суперускорители GH200 NVL32 и GB200 NVL72. И именно их NVIDIA считает минимальной эффективной единицей кластеров ближайшего будущего, предлагая крупным заказчикам на меньшее даже не размениваться.
Intel в семействе Gaudi использует Ethernet (1,2 Тбайт/с на ускоритель) как для вертикального, так и для горизонтального масштабирования. AMD же полагается на Infinity Fabric (896 Гбайт/с на ускоритель) на базе PCIe и xGMI, которые до недавнего времени за пределы узла не выходили. Однако в конце 2023 года было объявлено, что в 2025 году AMD и Broadcom выпустят коммутатор на базе PCIe 7.0 (стандарт планируют только-только утвердить в этом же году), который будет поддерживать технологию, которая теперь называется AFL (Accelerated Fabric Link) — это и будет выходом Infinity Fabric за пределы узла.
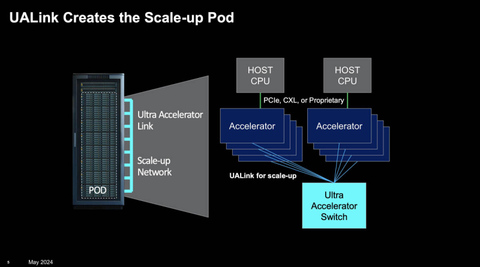
И именно совместными наработками AMD и Broadcom поделятся в рамках UALink. Первую версию нового интерконнекта альянс обещает представить уже в III квартале 2024 года, а в IV квартале — версию 1.1. При этом пока прямо не говорится, будет ли основным транспортом PCIe или Ethernet, и какой протокол будет использоваться для работы с памятью. Но уже обещано, что UALink 1.0 позволит объединить до 1024 ускорителей в одном домене с возможностью прямых load/store-запросов к их памяти. Для дальнейшего масштабирования кластеров по-прежнему предлагается использовать Ultra Ethernet.
При этом UALink, строго говоря, не обещает возможности беспрепятственного общения ускорителей разных вендоров, зато позволяет упростить инфраструктуру и сделать её дешевле благодаря открытости и конкуренции. Хотя было бы приятно увидеть UALink в качестве аппаратной основы и для стандарта UXL, который намерен побороться с NVIDIA CUDA. Что касается CXL, то этот стандарт, тоже использующий PCIe в качестве транспорта, вероятно, останется «привязанным» к CPU и внутриузловым коммуникациям, хотя возможности его гораздо шире.
Источник: servernews.ru