Архитектура LSTM была предложена в 1997 году немецкими исследователями Зеппом Хохрайтером и Юргеном Шмидхубером. С тех пор она выдержала испытание временем: с ней связано много прорывов в глубоком обучении, в частности именно LSTM стали первыми большими языковыми моделями.
Однако появление трансформеров в 2017 году ознаменовало новую эру, и популярность LSTM пошла на спад. Трансформеры оказались более масштабируемой архитектурой, к тому же способной хранить гораздо больше информации.
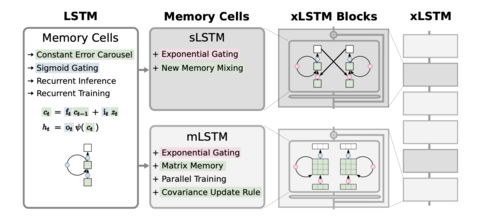
На днях, спустя 27 лет, создатели LSTM предложили улучшение своей технологии – xLSTM. Благодаря нововведениям xLSTM теперь может конкурировать с трансформерами и по перформансу, и по масштабируемости.
Ученым удалось внедрить экспоненциальные гейты вместо сигмоидальных, новый алгоритм смешивания памяти, матричную память вместо скалярной и альтернативное правило обновления ковариаций.
Если звучит непонятно, на нашем сайте уже вышел полный разбор статьи про xLSTM, в котором вы найдете:
Пошаговое объяснение того, как работает ванильная LSTM. Разберетесь, даже если вы ничего не слышали про эту архитектуру до этого.
Структурированный разбор каждого улучшения, которое предложили ученые в xLSTM.
Множество схем и примеров.
Сравнение xLSTM с трансформерами.
Ответа на вопрос «заменят ли xLSTM трансформеры?» пока нет. Некоторые в ML сообществе настаивают на том, что это прорыв, другие в xLSTM не верят. Ясно одно: эта архитектура – новый виток Deep Learning и NLP, и она обладает большим потенциалом.
Будем ждать на эту тему еще больше исследований и новостей! Подпишитесь на нас в Telegram, чтобы ничего не пропустить: t.me/data_secrets.
Источник: habr.com