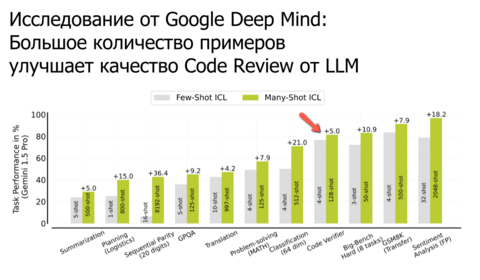
В пятницу вышла статья от исследователей из Google Deep Mind в которой они утверждают (на основе проведенных испытаний), что если положить в контекст LLM большое количество примеров подобных решаемой задаче, то результат будет лучше. Подход назвали Many-Shot In-Context Learning. В целом кажется логичным и не удивительно, что исследование провели разработчики LLM в которой есть контекстное окно в миллион токенов, в которое, собственно, можно положить это большое (сотни и даже тысячи) количество примеров.
Вот, например, как делали с проверкой адекватности кода: Взяли датасет скриптов решающих задания из датасета GSM8K (набор математических задач), у Гугла такой был c решениями от Gemini 1.0. Датасет представляет из себя набор программ (предположу, что на Python) с разметкой на корректные и некорректные решения. Так вот, если подложить в промпт 128 таких примеров, то точность в проверке кода от LLM (когда вы даете ей код и просите проверить корректность) повышается на 5% относительно случая когда в таком запросе было только 4 примера.
Как использовать в быту? Например, собрать хороший тематический датасет с корректным кодом и багами по проекту и добавить в контекст автоматического ревьюера кода.
Что интересно, также в исследовании отмечено, что датасет с примерами может быть синтетическим, или состоять только из похожих вопросов без ответов и это так же повышает эффективность решений от LLM. Ссылка на arixv.
Наш ТГ канал AI 4 Dev — где мы обсуждаем применение LLM в разработке программного обеспечения.
Источник: habr.com