«Лаборатория Касперского» рассказала об исследовании израильской компании Offensive AI Lab. В своём исследовании специалисты Offensive AI Lab описывают метод восстановления текста из перехваченных сообщений от чат‑ботов с ИИ и какую информацию можно извлечь из перехваченных сообщений чат‑ботов на основе ИИ.
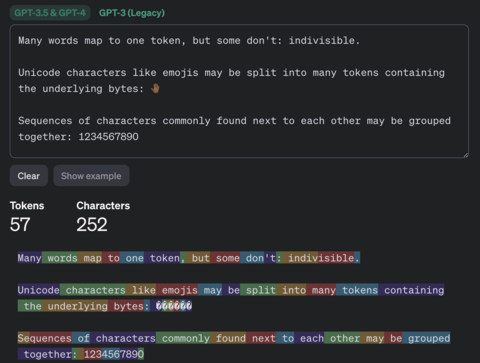
Чат‑боты отправляют сообщения в зашифрованном виде, но в реализации самих больших языковых моделей (LLM) и основанных на этих моделях чат‑ботов есть ряд особенностей. Из‑за этих особенностей эффективность шифрования снижается и позволяет провести так называемую атаку по сторонним каналам, когда содержимое сообщения удаётся восстановить по тем или иным сопутствующим данным. Большие языковые модели оперируют не отдельными символами и не словами, а токенами.
Пример токенизации текста моделями GPT-3.5 и GPT-4
Сами чат‑боты присылают ответ не крупными кусками, а постепенно, если бы его печатал человек. Как уже говорилось, LLM пишут не отдельными символами, а токенами. Поэтому чат‑бот отправляет сгенерированные токены в режиме реального времени, один за другим, исключение составляет Google Gemini (он не подвержен описываемой в исследовании атаке).
На момент публикации исследования большинство существующих чат‑ботов, перед тем как зашифровать сообщение, не использовали сжатие, кодирование или дополнение (это метод повышения криптостойкости, где к полезному сообщению добавляются мусорные данные, чтобы снизить предсказуемость).
Использование описанных особенностей делает возможным атаку по сторонним каналам. Сами перехваченные сообщения от чат‑бота невозможно расшифровать, но из них можно извлечь полезные данные, например, длину каждого из отправленных чат‑ботом токенов.
Для восстановления текста сообщения надо угадать, какие слова скрываются за «пустыми клетками» (токенами). Для этого можно использовать большие языковые модели. Именно для восстановления текста исходного сообщения из полученной последовательности длин токенов исследователи использовали именно несколько LLM.
Исследователи предположили, что начальные сообщения в разговорах с чат‑ботами почти всегда шаблонны и их легче всего угадать, обучив модель на массиве вступительных сообщений, сгенерированных популярными языковыми моделями. Поэтому одна модель реконструирует вводные сообщения, а другая модель, которая занимается остальным текстом беседы.
После описанных действий получается некий текст, где длины токенов соответствуют длинам токенов в оригинальном сообщении, а конкретные слова могут быть подобраны с той или иной степенью успешности. Однако полное соответствие восстановленного сообщения оригиналу случается довольно редко, потому что какую‑то часть слов правильно угадать не получается. И естественно, в неудачном случае воссозданный текст может иметь мало общего с оригиналом.
Пример удачной реконструкции текстаПример не очень удачной реконструкции текстаПример крайне неудачной реконструкции текста
Исследователи рассмотрели 15 существующих чат‑ботов на основе ИИ и признали большинство из них уязвимыми для данной атаки исключение составляют уже озвученный Google Gemini (в девичестве Bard) и GitHub Copilot (не Microsoft Copilot). В рамках исследования, специалисты рассказали, что даже общую тему беседы им удавалось правильно установить в 55% случаев, а успешно восстановить текст только в 29%.
По словам «Лаборатории Касперского», у описанной атаки есть ещё одно ограничение, о котором Offensive AI Lab не упоминает. Успешность восстановления текста сильно зависит от языка, на котором были написаны перехваченные сообщения, потому что токенизация работает для разных языков по‑разному. Для английского языка, на котором и была продемонстрирована эффективность этой атаки, характерны очень длинные токены. Поэтому токенизация текста на английском даёт выраженные паттерны, по которым сравнительно легко восстанавливать текст. Все остальные языки менее удобны для атаки. Даже для близких к английскому языков германской и романской групп средняя длина токена в 1,5–2 раза меньше, а для русского — в 2,5. Типичный «русский токен» имеет длину всего в пару символов, что, скорее всего, сведёт эффективность атаки к нулю.
Разработчики Cloudflare и OpenAI уже отреагировали на публикацию исследования и начали использовать упомянутый выше метод дополнения (padding), придуманный для противодействия такого рода атакам.
Источник: habr.com